Java: How To Autodetect The Charset Encoding of A Text File and Remove Byte Order Mark (BOM)
TLDR;
Required dependencies (pom.xml) :
<dependency>
<groupId>com.ibm.icu</groupId>
<artifactId>icu4j</artifactId>
<version>60.1</version>
</dependency>
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.6</version>
</dependency>
Autodetect the charset encoding of a text file or input stream then ‘remove’ (skip) Byte Order Mark (BOM) while reading based on detected charset :
File inputFile = new File("/Users/fahri/Downloads/UNKNOWN_TEXT.txt");
BOMInputStream bomInputStream = new BOMInputStream(new BufferedInputStream(new FileInputStream(inputFile)),
ByteOrderMark.UTF_8, ByteOrderMark.UTF_16BE, ByteOrderMark.UTF_16LE, ByteOrderMark.UTF_32BE, ByteOrderMark.UTF_32LE);
System.out.println("HAS BOM : " + bomInputStream.hasBOM());
CharsetDetector detector = new CharsetDetector();
detector.setText(bomInputStream);
CharsetMatch charsetMatch = detector.detect();
System.out.println("CHARSET MATCH : " + charsetMatch.getName());
BufferedReader br = new BufferedReader(new InputStreamReader(bomInputStream, charsetMatch.getName()));
for (String line = br.readLine(); line != null; line = br.readLine()) {
System.out.println(line);
}
br.close();
Problem
You got a text file and you have no idea why your application could not process (parse) that file.
This is a sample of that file: UNKNOWN_TEXT.txt
Analyze The Content
cat
If we inspect the content using cat :
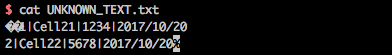
The content looks normal. But, wait.
What is that weird characters at the beginning and end ? (�� and %)
more
Display the content using another tool, more :

It looks weirder. <FF><FE> at the beginning and ^@ between the characters.
file
What file command says ?
$ file UNKNOWN_TEXT.txt
UNKNOWN_TEXT.txt: Little-endian UTF-16 Unicode text
The text file is a Little-Endian UTF-16 text and our viewer (iTerm2 on OSX, in this case) only supports UTF-8. That is why it looks not normal and your application can not process (parse) further.
hexdump
If we investigate in more detail using hexdump :
$ hexdump UNKNOWN_TEXT.txt
0000000 ff fe 31 00 7c 00 43 00 65 00 6c 00 6c 00 32 00
0000010 31 00 7c 00 31 00 32 00 33 00 34 00 7c 00 32 00
0000020 30 00 31 00 37 00 2f 00 31 00 30 00 2f 00 32 00
0000030 30 00 0a 00 32 00 7c 00 43 00 65 00 6c 00 6c 00
0000040 32 00 32 00 7c 00 35 00 36 00 37 00 38 00 7c 00
0000050 32 00 30 00 31 00 37 00 2f 00 31 00 30 00 2f 00
0000060 32 00 30 00
0000064
We can conclude that <FF><FE> and ^@ represents value ff fe and 00 in hex, respectively.
Endianness
UTF-16 represents a character using two bytes (2x8 byte=16, make sense, huh?). There are two ways to determine the order of the bytes 1 :
- Big Endian : you store the most significant byte in the smallest address
- Little Endian : you store the least significant byte in the smallest address
For the concrete example, these are characters Z in various encoding :
Character : Z
ASCII (in hex) : 5A
UTF16 Little Endian (in hex) : 5A 00
UTF16 Big Endian (in hex) : 00 5A
Byte Order Mark (BOM)
You already know the meaning of 00. Then, what exactly is ff fe in the first bytes ?